404 Brain Not Found
[자료구조] PriorityQueue 본문
분류:
- 추상 자료형(Abstract Data Type)
- 힙(Heap) 기반 자료구조
특징:
- 각 요소가 우선순위를 가지며, 높은 우선순위의 요소가 먼저 나가는 큐
- 일반적으로 힙(주로 이진 힙)을 사용하여 구현됨
- 삽입(enqueue)과 삭제(dequeue) 연산의 시간 복잡도는 O(log n)
- 최고 우선순위 요소 접근은 O(1) 시간 복잡도
- 우선순위는 요소의 값 자체이거나 별도의 우선순위 값으로 정의될 수 있음
- 동일한 우선순위의 요소들 사이의 순서는 보장되지 않음
- 최대 우선순위 큐(max-priority queue)와 최소 우선순위 큐(min-priority queue)로 구현 가능
사용처:
- 운영체제의 작업 스케줄링 (높은 우선순위 프로세스 먼저 실행)
- 네트워크 패킷 라우팅 (QoS 기반 패킷 처리)
- 이벤트 드리븐 시뮬레이션
- 허프만 코딩 알고리즘 (데이터 압축)
- 다익스트라 알고리즘 등 그래프 알고리즘
- 응급실에서의 환자 처리 순서 결정
- 프린터의 인쇄 작업 관리
- 실시간 시스템에서의 인터럽트 처리
- 경매 시스템에서의 입찰 관리
- 인공지능의 최선 우선 탐색(Best-First Search) 알고리즘
#pragma once
#include "HeapTree.h"
/*
HeapTree
*/
template<typename T>
class PriorityQueue
{
private:
// 이전에 구현하였던 HeapTree를 그대로 사용
HeapTree<T> _heapTree;
public:
void Push(const T& data); // 데이터 삽입
void Pop(); // 데이터 삭제
const T& Top(); // 우선순위가 가장 높은 값
bool Empty(); // 우선순위 큐가 비었는지 확인
};
template<typename T>
inline void PriorityQueue<T>::Push(const T& data)
{
_heapTree.Push(data);
}
template<typename T>
inline void PriorityQueue<T>::Pop()
{
_heapTree.Pop();
}
template<typename T>
inline const T& PriorityQueue<T>::Top()
{
return _heapTree.Top();
}
template<typename T>
inline bool PriorityQueue<T>::Empty()
{
return _heapTree.Empty();
}#include "pch.h"
#include "PriorityQueue.h"
int main()
{
PriorityQueue <int> pq;
pq.Push(3);
pq.Push(1);
pq.Push(4);
pq.Push(20);
pq.Push(13);
pq.Push(5);
pq.Push(6);
pq.Push(8);
pq.Push(999);
pq.Push(14);
pq.Push(12);
while (!pq.Empty())
{
std::cout << pq.Top() << " ";
pq.Pop();
}
return 0;
}
실행 결과

구현 중요 포인트
우선순위 큐는 정말 활용도가 높고, 알고리즘 문제에서 많이 출제되는 유형입니다.
우선순위 큐는 힙트리를 이용해서 구현이 됩니다.
[자료구조] HeapTree
분류:비선형 자료구조완전 이진 트리(Complete Binary Tree) 기반우선순위 큐를 위해 고안된 자료구조특징:부모 노드와 자식 노드 간의 대소 관계가 일정한 완전 이진 트리최대 힙(Max Heap): 부모 노드
benjaminhoward.tistory.com
그렇기에 저는 이전에 힙 트리를 이용해서 그대로 구현하였습니다.
이대로 우선순위 큐 내용을 끝내면 아쉬우니깐, 왜 우선순위큐를 사용해야 하는지 예시를 들어보겠습니다.
어떻게 예시를 들것이냐면, 동적배열(ArrayList)와 우선순위 큐(PriorityQueue) 두가지의 성능을 비교해보도록 하겠습니다.
[자료구조] ArrayList
분류:선형 자료구조동적 배열 기반 자료구조특징:내부적으로 배열을 사용하여 요소를 저장크기가 동적으로 조절됨 (자동으로 크기가 증가하거나 감소)인덱스를 통한 랜덤 접근이 가능 (O(1) 시
benjaminhoward.tistory.com
먼저, ArrayList를 이용해서 우선순위 큐 처럼 사용하려면, 최대값을 찾은 후, 최대값을 반환해야 할 것 입니다. 이때, 선형 자료구조에서 데이터를 찾기 위해서는 N개 만큼의 데이터를 탐색해야 하므로, O(N) 시간 복잡도를 가지게 됩니다. 그리고 여기서 끝나는 것이 아니라, 찾은 데이터를 삭제를 해줘야 합니다. 삭제를 해주기 위해서는 뒤에 있는 데이터를 당겨서 삭제 데이터에 삽입을 해줘야 합니다. 그림으로 표현하자면...
[1][D][3][2][4] (삭제 전)
[1][3][2][4][4] (삭제 후)
이렇게 처리를 하기 위해서 또, 당기는 작업이 필요한데 그것 또한 O(N)의 시간복잡도를 가지게 됩니다.
우선 지금까지 제가 설명한걸 하나의 함수로 구현해보겠습니다.

이런식으로 구현을 해주었습니다. 그 다음, ArrayList 클래스에 기능을 더 추가해주었습니다.

좀더 유연하게 배열에 접근하기 위하여 [] 연산자를 오버로딩 해주었습니다.

동적배열에서 데이터를 삭제하는것을 구현해주었습니다.
애초에 동적 배열에서 가장 마지막 부분을 삭제하는것은 효율적이지만, 중간에 데이터를 삭제하는것은 비효율적입니다.
그렇기에 웬만하면 설계를 할때 중간에 삽입, 삭제가 일어나면 다른 자료구조를 사용합니다.
그 다음, Windows API를 사용하여 CurrentTick을 계산해서, 우선순위 큐를 사용할때와 ArrayList를 사용할때
시간 차이가 얼마나 발생하는지 확인해보겠습니다. Windows.h를 인클루드 해준 후, 아래의 코드를 작성합니다.
int main()
{
// 입력 테스트 데이터 숫자
#define DataCnt 100
int srand(time(nullptr)); // Tick을 세기 위한 시간 초기화
{
int startTick = ::GetTickCount64(); // 현재 시간 계산
std::cout << "-------- PriorityQueue Start--------" << std::endl;
PriorityQueue <int> pq;
for (int i = 0; i < DataCnt; i++) // 랜덤으로 데이터 넣기
{
int random = rand() % 10000;
pq.Push(random);
}
while (!pq.Empty())
{
std::cout << pq.Top() << " ";
pq.Pop();
}
std::cout << std::endl;
int endTick = ::GetTickCount64(); // 마지막 시간 계산
std::cout << "-------- PriorityQueue Tick " << endTick - startTick << "--------" << std::endl;
}
std::cout << std::endl;
// 주석 생략
{
int startTick = ::GetTickCount64();
std::cout << "-------- ArrayList Start--------" << std::endl;
ArrayList<int> arr;
for (int i = 0; i < DataCnt; i++)
{
int random = rand() % 10000;
arr.PushBack(random);
}
while (!arr.Empty())
{
std::cout << FindPrioritySearch(arr) << " ";
}
std::cout << std::endl;
int endTick = ::GetTickCount64();
std::cout << "-------- ArrayList Tick " << endTick - startTick << "--------" << std::endl;
}
return 0;
}
처음에는 간단하게 100개만 테스트 해보겠습니다.

100 개만 테스트 했을때는 시간차이가 얼마 나지 않습니다.하지만 데이터가 많아지면 차이가 발생할 것 입니다. 그러면 우선 콘솔에 출력하는것을 지우고, 데이터 숫자를 1만으로 늘려보겠습니다.

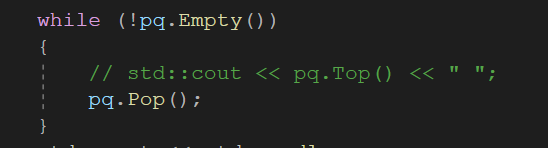

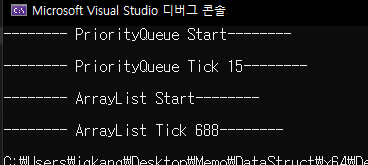
1만개의 데이터를 기준으로 우선순위 큐는 15 Tick 발생하였고, ArrayList는 688 Tick 만큼 걸렸습니다.
이제 왜 우선순위 큐를 사용해야 하는지 이해할 수 있습니다.
'자료구조 > 비선형자료구조' 카테고리의 다른 글
| [자료구조] BinarySearchTree (C++ 버전, C언어 버전) (4) | 2024.09.16 |
|---|---|
| [자료구조] Graph + 객체지향 다형성 활용 (5) | 2024.09.16 |
| [자료구조] HeapTree (1) | 2024.09.16 |


